 Add Row
Add Row  Add
Add 

Unleashing the Power of AI Responsiveness
In today's fast-paced digital landscape, reducing latency is paramount for organizations looking to harness the full potential of artificial intelligence (AI). As enterprises increasingly adopt AI frameworks, especially those built on platforms like Amazon Bedrock, being able to respond swiftly to user requests is critical. Latency-optimized inference is not merely a technicality—it's a cornerstone of effective user engagement and operational efficiency.
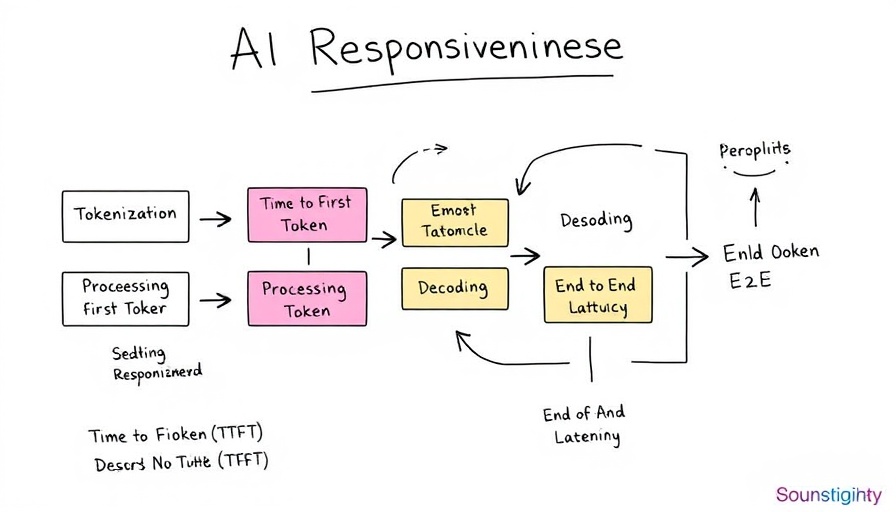
Understanding Latency-Optimized Inference
Latency refers to the time delay between a user's query and the system's response. In AI applications, every millisecond counts. Amazon Bedrock provides a framework that facilitates optimal inference times, allowing businesses to deliver faster outputs in their AI-driven interactions. This optimization becomes particularly important in sectors such as e-commerce, healthcare, and customer service, where swift decision-making is essential.
Current Trends in AI and Business Responsiveness
As organizations pivot toward AI technologies, industry trends indicate a significant shift in how responsiveness is perceived. Companies are realizing that effective AI deployment translates to increased customer satisfaction and improved bottom lines. Technologies that offer low latency responses can enhance user experience, streamline workflows, and bolster decision-making frameworks within businesses. Integration of AI in crucial sectors underscores the necessity of speed alongside accuracy.
Practical Strategies for Optimizing AI Performance
To maximize the benefits of AI in a business context, here are several actionable insights for CEOs, CMOs, and COOs:
- Evaluate Your Infrastructure: Assess whether existing hardware effectively supports low-latency processes. It is crucial to ensure that network configurations and server locations are optimized for speed.
- Leverage Edge Computing: Utilizing edge computing capabilities can greatly reduce response times by processing data closer to where it is generated, thus minimizing lag.
- Choose the Right Algorithms: The choice of AI algorithms can significantly impact inference speed. Focus on those that are engineered for quick responsiveness while maintaining diagnostic fidelity.
- Continuous Monitoring: Employ monitoring tools that provide real-time analytics to understand latency bottlenecks. Adjust configurations based on these insights to continually enhance performance.
The Future of AI Responsiveness in Business
The journey toward ultra-responsive AI is just beginning. As technology progresses, we can anticipate innovations that will further decrease latency in AI applications. Solutions that deliver real-time insights and predictions will become invaluable, supporting not only enhanced customer experiences but also fueling innovation across sectors.
Conclusion: Why Responsiveness Matters
For leaders aiming to stay ahead in the competitive landscape, optimizing AI responsiveness is not merely an operational consideration—it's a strategic imperative. Understanding and implementing latency-optimized inference will enable organizations to create agile, responsive business models that meet the ever-evolving demands of their customer base.



Write A Comment