 Add Row
Add Row  Add
Add 

Unlocking the Future of Text Classification with R.E.D.
In today's data-driven landscape, organizations are constantly seeking innovative solutions to tackle complex challenges, particularly in text classification. With the advent of Large Language Models (LLMs), many classification problems can now achieve commendable results, hovering around 70-90% accuracy through effective prompt engineering. However, what if the demand exceeds these capabilities? This is where the novel Recursive Expert Delegation (R.E.D.) framework enters the scene.
Defining the Classification Challenge
Text classification has long been considered a cornerstone of supervised learning, yet it presents a myriad of challenges. Achieving high performance with numerous classes, particularly when training data is scarce per class, has proven daunting. The intricacies involve: a limited amount of training data, a growing number of classes, rapid training requirements, and the costs associated with using LLMs.
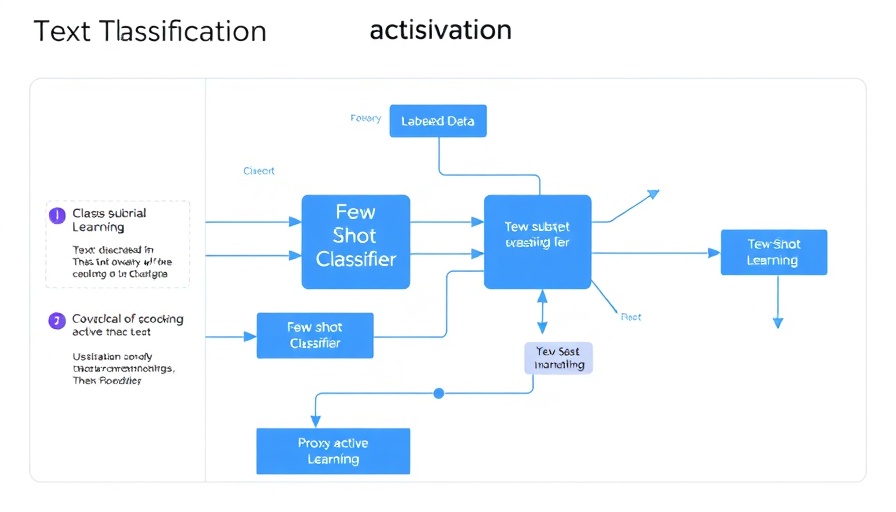
Introducing R.E.D.: A Game Changer in Classification
R.E.D. is not just another theoretical construct; it is an applied ML paradigm tailored for real-world applications. Rather than relying solely on a singular classifier to handle extensive label spaces, R.E.D. opts for a more strategic approach by segmenting classes into manageable subsets. Through this “divide and conquer” method, it fosters the development of specialized classifiers for each subset of labels, thereby enhancing accuracy and efficiency in classification tasks.
The Mechanics Behind R.E.D.
The R.E.D. framework operates on a semi-supervised learning model, ideal for scenarios with around 100 to 1000 classes, each possessing a mere 30 to 100 samples. This model streamlines the classification process through the following key steps:
- Label Subset Division: Break down the expansive label space into smaller, more manageable groups.
- Efficient Learning: Craft tailored classifiers that focus on each specific subset, ensuring accuracy while minimizing training data usage.
With R.E.D., organizations can address the pressing challenge of data scarcity, thus maximizing the utility of their existing data assets.
Why Companies Should Consider R.E.D. Now
The implications of R.E.D. extend beyond mere academic interest; they resonate deeply within the operational frameworks of fast-growing enterprises. Not only does this algorithm help maintain competitive advantages in classification precision, but it also facilitates a smoother transition into digital transformation journeys. For C-suite executives and decision-makers in tech, finance, and healthcare, adopting R.E.D. could significantly enhance data handling capabilities amidst a rapidly evolving digital landscape.
Conclusion: Embracing R.E.D. for Future-Ready Solutions
As the challenges of text classification become more complex and pervasive, frameworks like R.E.D. represent a pivotal advancement in addressing these hitches. By allowing organizations to make informed, strategic decisions on classification technologies that drive efficiency and precision, R.E.D. sets the foundation for a more adaptive and sustainable future in digital transformation.
In conclusion, for businesses striving to streamline their operations while enhancing their technological capabilities, exploring the potential of R.E.D. may well be the step they need to take to implement innovative solutions today. Start your journey in transforming text classification by looking into R.E.D.—the resolution for a smarter, more efficient classification system.



Write A Comment